Data GovernanceData QualityData QualtyData StrategyTech Trends
Microsoft is rolling out its CoPilot tool across the Microsoft 365 world. It promises the best of both worlds: your organisation’s data combined with the power of Large Language Models. The shiny future on the hill is a world of perfect productivity. Searching for information and drafting documents becomes easy through the use of narrative prompting through a “chatbot” style interface. The potential to link in external data from other company systems via Microsoft Graph dangles a promise. A promise of better searching for answers and speedier generation of outputs across the whole enterprise.
Cool.
At Castlebridge we like to be skeptical friends when it comes to adopting new technologies to put data to work. After all, we’ve been around the block a few times. In our experience, the final outcome is often far from the hoped for pitch.
The Importance of the Data Foundations
The unfortunate reality is that these tools rely on your underlying data to develop their model of your world. If data is poorly managed and governed, or of questionable quality, the effectiveness of tools used to interrogate that data is lessened. This is true whether you are using a fancy LLM-based system, a humble SQL query, or a string-based search.
However, the promised ease of use of chat-based interfaces to simplify search and improve productivity depends on the quality of that data. Crucially it will depend on the quality of the underlying metadata. That metadata includes (but is not limited to) things like:
Document classification and categorisation (including emails, documents, presentations etc)
User access rights and controls to prevent ‘over sharing’ of data and information
Metadata about the currency, accuracy, or ‘fitness for use’ of data or records being used by the LLM to respond to the prompt.
In short, this all depends on things that organisations, in general, have not been very good at over the years. Ironically, these are the things that, if we had done them well and consistently in the past, we would have better data and records management control and better ‘searchability’ and ‘findability’ for data, even without the power of an LLM-based tool.
How the Magic Happens
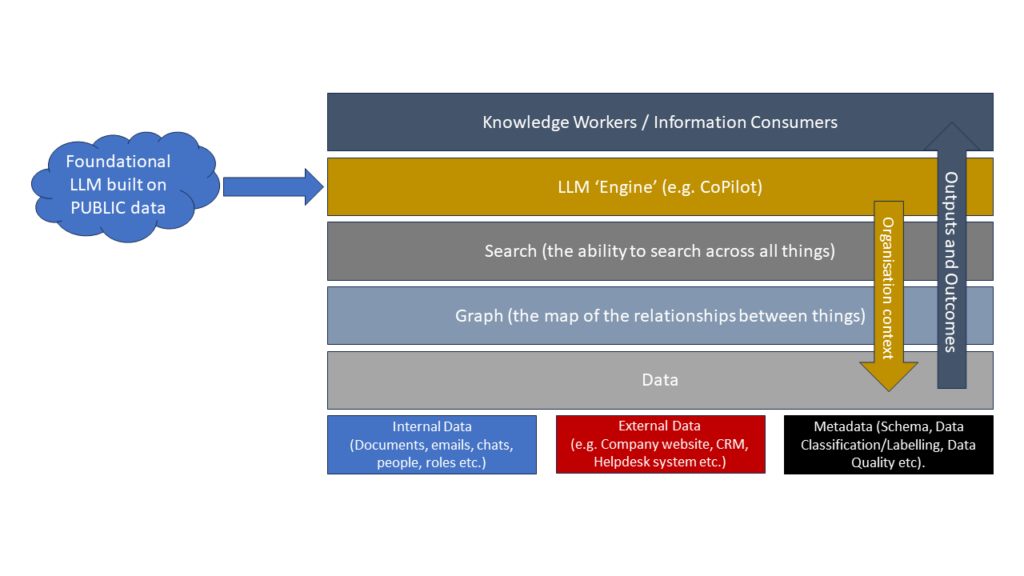
The graphic below is a simplified representation of how a tool like Microsoft CoPilot works.
Simplified description of LLM tool operating internally in a business environment
When you deploy your LLM CoPilot in to the organisation, it comes pre-loaded with the insights, knowledge, and biases of the original public training data that helped develop its predictive model. We then apply that to the data and content in the organisation. And hope that it works well. It’s analogous to hiring a junior member of staff and expecting them to be able to immediately search and find the right things for you in your SharePoint or other repositories. And it has the added bonus that this digital intern will forget the context of things in your searches with every query and will rely on your metadata each time they go looking for something.
Even a CoPilot needs data to navigate by
So, the quality of your CoPilot’s navigation to infer and predict the correct outputs in response to your prompt will depend on the quality of metadata and the curation of content. And the risk of your tool unearthing and disclosing information that people should not be aware of (e.g. commercially sensitive data, information that might be subject to intellectual property restrictions, or personal data of staff or customers which shouldn’t be shared within the organisation) likewise is a function and factor of your general data governance and your historic approach to Document and Content Management and Metadata management.
It’s not just me saying this. This is what Microsoft say in their documentation for IT Admins on getting ready for CoPilot:
“Microsoft 365 Copilot uses your existing permissions and policies to deliver the most relevant information, building on top of our existing commitments to data security and data privacy in the enterprise. This means it is important to have good content management practices in the first place. For many organizations, content oversharing, and data governance can be a challenge.“
The last bit in bold is a bit of an understatement, to say the least. Particularly when we add in the important context that Microsoft CoPilot will use all the organisational data within your Microsoft 365 tenant (and any external tool you connect into the Microsoft Graph, such as your CRM system) to deliver the ‘experiences’. Access will be based on user access rights to content. Which raises further metadata and data governance challenges in ensuring role appropriate user access controls are in place and operate effectively.
CoPilot or Coprolite?
Depending on the level of organisation maturity in data fundamentals, LLMs in the internal business context have a lot of potential. Either it will be a trusted copilot, helping you to navigate a course through the accumulated documents, content, and other data in your organisation to get to your destination and execute tasks efficiently and effectively.
Or it will be a crutch that staff rely on, blindly accepting the outputs without critical examination of quality, accuracy, or relevance, leading to what air crash investigators would call “controlled flight into terrain”. After all, without metadata to tell the AI pilot that goats don’t levitate, it might not see the mountain dead ahead.
Alternatively, it will create an ossification of your organisation as stakeholders and knowledge workers become bogged down in inconsistent responses, dealing with unauthorised disclosure of confidential information (that wasn’t properly tagged or otherwise restricted), potential hallucinations in the LLM caused by the predictive nature of Large Language models, or simply delay and distraction from staff trying to craft the perfect prompt to get the desired output. And that is Coprolite.
Preparing a Flight Plan for your CoPilot
Castlebridge recommends that organisations thinking about adopting tools like Microsoft CoPilot do so with care. You should take time to examine your current data and records/document management and data governance practices and information security controls. Tools like CoPilot will not be free to implement. The return on investment from the use of these tools will depend entirely on the data foundations you build on.
Improving organisational maturity in managing and applying metadata, improving and implementing document and data classification schemes, and ensuring that there are appropriate access controls applied to data is an essential first step to leveraging the potential of tools such as these in an organisation. It is likely that the efforts made to address fundamentals will have a significant impact on the problems your organisation thinks the AI will help you fix. Without actually implementing the AI.
Organisational leadership needs to recognise that the investment in these foundations is simply the accumulated data and technical debt of the organisation falling due.
It will also be more important than ever to think about how we train and onboard staff. In particular staff in junior roles. These might traditionally have learned what ‘good’ looks like by drafting and reviewing documents, building presentations, or summarising meeting notes. People implementing new technologies have had the benefit of that learning curve and may not immediately recognise its value. We need to make sure that, even if we have an AI-enabled tool to prepare draft documents, that we have a HI (human intelligence) that knows enough to be able to review and correct that first draft.